
ICS - Arch Lab | 处理器太慢怎么办?
在 Arch Lab 中,我们将熟悉流水线 Y86-64 处理器的设计与实现,并对该处理器及一个基准测试程序进行优化,以实现性能最大化。实验分为三个部分:
- Part A:编写一些简单的 Y86-64 程序,并熟悉 Y86-64 相关工具的使用。
- Part B:为 SEQ 模拟器扩展新的指令并完善 CPU 流水线的实现过程。
- Part C:对 Y86-64 基准测试程序及其架构设计进行优化。
预备知识
Y86-64 指令集架构
Y86-64 是基于 x86-64 简化而来的指令集,定义了指令格式、寄存器组、寻址方式及程序状态码,是 Arch Lab 中处理器设计的指令规范。
HCL 硬件描述语言
HCL 是用于描述硬件逻辑的简化语言,重点支持组合逻辑与时序逻辑表达,是实现处理器模拟器控制逻辑的核心工具。
SEQ 架构
SEQ 是基础的单周期处理器架构,每条指令的取指、译码、执行等阶段串行完成,是理解流水线架构的基础模型。
PIPE 架构
PIPE 是将指令执行拆解为多个流水线阶段并行处理的架构,可提升指令吞吐量,需解决数据冒险、控制冒险等关键问题。
前置准备
环境配置
参考指导文档进行环境配置。
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
rustup install 1.90
rustup default 1.90在每次更改 Rust 源码后,应重新构建项目。
cd archlab-project
cargo build工具集
构建项目后,将产生一个 archlab-project/target 文件夹来存储输出的二进制文件和其他中间文件。输出的可执行文件是:
- Y86-64 汇编器:target/debug/yas
- Y86-64 调试器:target/debug/ydb
- Y86-64 ISA 模拟器:target/debug/yis
- Y86-64 流水线模拟器:target/debug/ysim
- 本地评分器:target/debug/grader
可通过以下命令启动本地评分器:
cd archlab-project
cargo build
./target/debug/grader part-a
./target/debug/grader part-b
./target/debug/grader part-c
./target/debug/grader autolab其余工具详情可参看 archlab-project/README.md。
git init
为了便于管理代码版本,笔者建议在 archlab-project 目录下初始化一个 Git 仓库:
cd archlab-project
git init用于追踪代码变更。
Part A
Part A 中,我们将在 archlab-project/misc 目录下开展工作。我们的任务是编写三个 Y86-64 程序实现三个函数。
sum.ys
参照给出的示例代码:
/* linked list element */
typedef struct ELE {
long val;
struct ELE *next;
} *list_ptr;
/* sum_list - Sum the elements of a linked list */
long sum_list(list_ptr ls)
{
long val = 0;
while (ls) {
val += ls->val;
ls = ls->next;
}
return val;
}这是一段链表的求和函数,我们可以在 sum.ys 中编写如下 Y86-64 程序:
.pos 0 ; 设置当前汇编地址为0(程序起始地址)
irmovq stack, %rsp ; 初始化栈指针%rsp,指向stack标签处(栈起始地址)
call main ; 调用main函数
halt ; 程序执行结束,停机
.align 8 ; 后续数据按8字节对齐
ele1: ; 链表第一个节点
.quad 0x00d
.quad ele2
ele2: ; 链表第二个节点
.quad 0x0e0
.quad ele3
ele3: ; 链表第三个节点
.quad 0xf00
.quad 0
main: ; main函数入口
irmovq ele1, %rdi ; 将第一个链表节点ele1的地址存入%rdi
call sum_list ; 调用sum_list函数
ret
sum_list: ; sum_list函数入口
xorq %rax, %rax ; 将%rax清零
Loop: ; 遍历链表
andq %rdi, %rdi ; 检查%rdi是否为0
je Done ; 若%rdi为0(链表结束),跳转到Done
mrmovq (%rdi), %rcx ; 从%rdi指向的地址(当前节点的val字段)读取值到%rcx
addq %rcx, %rax ; 将%rcx(当前节点val)加到%rax
mrmovq 8(%rdi), %rdi ; 从%rdi+8地址(当前节点的next字段)读取下一个节点地址到%rdi
jmp Loop ; 跳回Loop,继续处理下一个节点
Done: ; 遍历结束
ret
.pos 0x200 ; 设置栈的起始地址为0x200(确保栈有足够空间)
stack: ; 栈起始位置标记rsum.ys
参照给出的示例代码:
/* linked list element */
typedef struct ELE {
long val;
struct ELE *next;
} *list_ptr;
/* rsum_list - Recursive version of sum_list */
long rsum_list(list_ptr ls)
{
if (!ls)
return 0;
else {
long val = ls->val;
long rest = rsum_list(ls->next);
return val + rest;
}
}这是一段链表的递归求和函数,我们可以在 rsum.ys 中编写如下 Y86-64 程序:
.pos 0 ; 设置当前汇编地址为0(程序起始地址)
irmovq stack, %rsp ; 初始化栈指针%rsp,指向stack标签处(栈起始地址)
call main ; 调用main函数
halt ; 程序执行结束,停机
.align 8 ; 后续数据按8字节对齐
ele1: ; 链表第一个节点
.quad 0x00d
.quad ele2
ele2: ; 链表第二个节点
.quad 0x0e0
.quad ele3
ele3: ; 链表第三个节点
.quad 0xf00
.quad 0
main: ; main函数入口
irmovq ele1, %rdi ; 将第一个链表节点ele1的地址存入%rdi
call rsum_list ; 调用递归求和函数rsum_list
ret
rsum_list: ; rsum_list函数入口
andq %rdi, %rdi ; 检查%rdi(当前链表节点地址)是否为0(判断是否为空节点)
je Else ; 若为空节点(链表结束),跳转到Else(递归终止条件)
pushq %rbx ; 保存%rbx(被调用者保存寄存器,递归调用中需保留其值,避免被后续调用覆盖)
mrmovq (%rdi), %rbx ; 从当前节点(%rdi指向)的val字段读取值到%rbx(暂存当前节点的值)
mrmovq 8(%rdi), %rdi ; 从当前节点的next字段(%rdi+8地址)读取下一个节点地址到%rdi(更新参数为下一个节点)
call rsum_list ; 递归调用rsum_list,计算剩余链表的和(结果将存于%rax)
addq %rbx, %rax ; 将当前节点的值(%rbx)加到剩余链表的和(%rax)中,得到当前链表的总和
popq %rbx ; 恢复%rbx的值(从栈中弹出之前保存的值)
ret ; 返回当前计算的总和(结果在%rax中)
Else: ; 递归终止条件标签(空链表处理)
xorq %rax, %rax ; 将%rax清零(空链表的和为0,作为递归的基线返回值)
ret ; 返回0(结果在%rax中)
.pos 0x200 ; 设置栈的起始地址为0x200(确保栈有足够空间)
stack: ; 栈起始位置标记bubble.ys
参照给出的示例代码:
/* bubble_sort - Sort long numbers at data in ascending order */
void bubble_sort(long *data, long count)
{
long *i, *last;
for(last = data + count - 1; last > data; last--) {
for(i = data; i < last; i++) {
if(*(i + 1) < *i) {
long t = *(i + 1);
*(i + 1) = *i;
*i = t;
}
}
}
}这是一段冒泡排序函数,我们可以在 bubble.ys 中编写如下 Y86-64 程序:
.pos 0 ; 设置当前汇编地址为0(程序起始地址)
irmovq stack, %rsp ; 初始化栈指针%rsp,指向stack标签处(栈起始地址)
call main ; 调用main函数(跳转到main执行,返回地址压栈)
halt ; 程序执行结束,停机
.align 8 ; 后续数据按8字节对齐
array: ; 待排序的数组(存储6个long类型元素)
.quad 0xbca ; 数组元素1:0xbca
.quad 0xcba ; 数组元素2:0xcba
.quad 0xacb ; 数组元素3:0xacb
.quad 0xcab ; 数组元素4:0xcab
.quad 0xabc ; 数组元素5:0xabc
.quad 0xbac ; 数组元素6:0xbac
; 寄存器用途说明:
; %rdi:存放数组起始地址data
; %rsi:存放数组元素个数count
; %rbx:存放当前内层循环变量i(地址)
; %rcx:存放外层循环变量last(地址)
; %rdx:临时变量(用于计算、比较等)
; %r9:常量1(用于减法运算)
; %r10:常量8(每个long元素占8字节,用于地址偏移计算)
; %r11、%r12:临时存放数组元素(用于比较和交换)
bubble_sort: ; 冒泡排序函数入口
irmovq $1, %r9 ; 初始化%r9为1(用于count-1等减法)
irmovq $8, %r10 ; 初始化%r10为8(每个元素8字节,地址偏移量)
rrmovq %rdi, %rcx ; 将数组起始地址data复制到%rcx(用于计算last初始地址)
rrmovq %rsi, %rdx ; 将元素个数count复制到%rdx(临时存储count)
subq %r9, %rdx ; %rdx = count - 1(计算last的索引偏移量)
Loop_1: ; 计算last初始地址的循环(last = data + (count-1)*8)
andq %rdx, %rdx ; 检查%rdx(剩余偏移次数)是否为0
je Loop_2 ; 若偏移次数为0,说明last初始地址计算完成,跳至外层循环入口
addq %r10, %rcx ; %rcx += 8(每次偏移一个元素地址,累计(count-1)次)
subq %r9, %rdx ; %rdx -= 1(剩余偏移次数减1)
jmp Loop_1 ; 继续循环计算last地址
Loop_2: ; 外层循环入口
rrmovq %rcx, %rdx ; 将当前last地址复制到%rdx
subq %rdi, %rdx ; %rdx = last - data(计算last与数组起始地址的偏移)
jle Done_2 ; 若偏移<=0(last <= data),外层循环结束,跳至Done_2
rrmovq %rdi, %rbx ; 初始化内层循环变量i为data(%rbx = data)
Loop_3: ; 内层循环入口
rrmovq %rcx, %rdx ; 将当前last地址复制到%rdx
subq %rbx, %rdx ; %rdx = last - i(计算i与last的偏移)
jle Done_3 ; 若偏移<=0(i >= last),内层循环结束,跳至Done_3
mrmovq (%rbx), %r11 ; 读取i指向的元素:%r11 = *i
mrmovq 8(%rbx), %r12 ; 读取i+1指向的元素:%r12 = *(i+1)
subq %r12, %r11 ; 计算*i - *(i+1)(用于比较大小)
jle Else ; 若*i <= *(i+1),无需交换,跳至Else
mrmovq (%rbx), %r11 ; 重新读取*i
mrmovq 8(%rbx), %r12 ; 重新读取*(i+1)
rmmovq %r11, 8(%rbx) ; 将*i存入i+1的位置:*(i+1) = *i
rmmovq %r12, (%rbx) ; 将*(i+1)存入i的位置:*i = *(i+1)
Else:
addq %r10, %rbx ; i += 1(地址加8,移动到下一个元素)
jmp Loop_3 ; 跳回内层循环,继续下一次迭代
Done_3: ; 内层循环结束
subq %r10, %rcx ; last -= 1(地址减8,移动到前一个元素)
jmp Loop_2 ; 跳回外层循环,继续下一次迭代
Done_2: ; 外层循环结束
ret ; 从bubble_sort函数返回
main: ; main函数入口
irmovq array, %rdi ; 将数组起始地址array存入%rdi
irmovq $6, %rsi ; 将元素个数6存入%rsi
call bubble_sort ; 调用冒泡排序函数bubble_sort
ret ; 从main函数返回(返回到call main的下一条指令,即halt)
.pos 0x200 ; 设置栈的起始地址为0x200(确保栈有足够空间)
stack: ; 栈起始位置标记Part B
Part B 中,我们将在 archlab-project/sim/src/architectures/extra 目录下开展工作。我们的任务是逐步完善一系列处理器架构。它们均使用 HCL 语言描述,我们只需修改相应的占位符为正确的表达式。占位符一共有三种:
- BOOL_PLACEHOLDER
- U8_PLACEHOLDER
- U64_PLACEHOLDER
seq_full.rs
在 seq_full.rs 中,我们需要扩展 SEQ 处理器以支持以下指令:
- iopq V, rB
Fetch 阶段,需要保证 IOPQ 是一条有效指令,需要读取寄存器和立即数。
bool instr_valid = icode in // CMOVX is the same as RRMOVQ
{ NOP, HALT, CMOVX, IRMOVQ, RMMOVQ, MRMOVQ,
OPQ, IOPQ, JX, CALL, RET, PUSHQ, POPQ };
// Does fetched instruction require a regid byte?
bool need_regids =
icode in { CMOVX, OPQ, IOPQ, PUSHQ, POPQ, IRMOVQ, RMMOVQ, MRMOVQ };
// Does fetched instruction require a constant word?
bool need_valC = icode in { IRMOVQ, RMMOVQ, MRMOVQ, JX, CALL, IOPQ };Decode 阶段,与 OPQ 指令类似,需要将 rB 设置为 srcB 从寄存器文件中取值,并将写入地址 dstE 设置为 rB。
// What register should be used as the B source?
u8 srcB = [
icode in { OPQ, RMMOVQ, MRMOVQ, IOPQ } : ialign.rB;
icode in { PUSHQ, POPQ, CALL, RET } : RSP;
true : RNONE; // Don't need register
];
// What register should be used as the E destination?
u8 dstE = [
icode in { CMOVX } && cnd : ialign.rB;
icode in { IRMOVQ, OPQ, IOPQ } : ialign.rB;
icode in { PUSHQ, POPQ, CALL, RET } : RSP;
true : RNONE; // Don't write any register
];Execute 阶段,需要指定 ALU 的输入,并更新条件码。
// Select input A to ALU
u64 aluA = [
icode in { CMOVX, OPQ } : reg_read.valA;
icode in { IRMOVQ, RMMOVQ, MRMOVQ, IOPQ } : ialign.valC;
icode in { CALL, PUSHQ } : NEG_8;
icode in { RET, POPQ } : 8;
// Other instructions don't need ALU
];
// Select input B to ALU
u64 aluB = [
icode in { RMMOVQ, MRMOVQ, OPQ, IOPQ, CALL,
PUSHQ, RET, POPQ } : reg_read.valB;
icode in { CMOVX, IRMOVQ } : 0;
// Other instructions don't need ALU
];
// Set the ALU function
u8 alufun = [
icode == OPQ : ifun;
icode == IOPQ : ifun;
true : ADD;
];
// Should the condition codes be updated?
bool set_cc = icode in { OPQ, IOPQ };其余阶段无需调整。
pipe_s3a.rs
在 pipe_s3a.rs 中,我们需要在 pipe_s2.rs 的基础上进一步优化。我们发现 pipe_s2 的关键路径长度为 7,而计算 f_pc 的依赖路径过长。为了减少 f_pc 的依赖路径长度,我们进一步拆分了流水线阶段,将解码阶段与随后执行、存储和写回阶段分开。然而,这样做引入了新的问题:
reg_read和reg_write现在位于不同的流水线阶段,这可能导致数据冒险。用于计算
f_pc的操作数也被拆分到不同的流水线阶段,这实际上是不正确的,因为在特定时间点位于不同流水线阶段的值属于不同的指令。
为了解决上述问题,我们在必要时对流水线寄存器实施阻塞或冒泡控制,确保等待一个额外的周期以保证计算结果的正确性。
pipe_s3a.rs 的占位符修改如下:
:==============================: Fetch Stage :================================:
u64 f_pc = [
// Call. Use instruction constant
// If the previous instruction is CALL, the constant value should be the next PC
// valC is from Fetch Stage, thus the last cycle
D.icode == CALL : D.valC;
// Taken branch. Use instruction constant
// U8_PLACEHOLDER == JX && e_cnd : U64_PLACEHOLDER;
E.icode == JX && e_cnd : E.valC;
// Completion of RET instruction. Use value from stack
// valM is from DEMW stage, thus the current cycle
// U8_PLACEHOLDER == RET : e_valM;
E.icode == RET : e_valM;
// Default: Use incremented PC
1 : F.valP;
];
:=======================: "Execute Stage (Execute)" :==========================:
u8 e_dstE = [
// U8_PLACEHOLDER == CMOVX && !BOOL_PLACEHOLDER : RNONE;
E.icode == CMOVX && !e_cnd : RNONE;
1 : E.dstE;
];
:========================: Pipeline Register Control :=========================:
// If a data hazard occurs, we need to wait for the data to be written to the
// registers before proceeding.
bool data_harzard = d_srcA != RNONE && d_srcA in { e_dstE, e_dstM }
// || U8_PLACEHOLDER != RNONE && BOOL_PLACEHOLDER;
|| d_srcB != RNONE && d_srcB in { e_dstE, e_dstM };
// bool f_stall = D.icode in { JX, RET } || BOOL_PLACEHOLDER;
bool f_stall = D.icode in { JX, RET } || data_harzard;
// bool d_stall = BOOL_PLACEHOLDER;
bool d_stall = data_harzard;pipe_s3b.rs
在 pipe_s3b.rs 中,我们需要在 pipe_s3a.rs 的基础上进一步优化。pipe_s3a 的一个问题是停顿和气泡的频率太高,这实际上降低了性能。除了使用停顿和气泡来处理数据冒险之外,也可以通过转发来解决。
pipe_s3b.rs 的占位符修改如下:
:==============================: Fetch Stage :================================:
u64 f_pc = [
// Call. Use instruction constant
// If the previous instruction is CALL, the constant value should be the next PC
// valC is from Fetch Stage, thus the last cycle
D.icode == CALL : D.valC;
// Taken branch. Use instruction constant
// U8_PLACEHOLDER == JX && e_cnd : U64_PLACEHOLDER;
E.icode == JX && e_cnd : E.valC;
// Completion of RET instruction. Use value from stack
// valM is from DEMW stage, thus the current cycle
// U8_PLACEHOLDER == RET : e_valM;
E.icode == RET : e_valM;
// Default: Use incremented PC
1 : F.valP;
];
:==============================: Decode Stage :================================:
u64 d_valA = [
// d_srcA == U8_PLACEHOLDER : e_valE;
// d_srcA == U8_PLACEHOLDER : e_valM;
d_srcA == e_dstE : e_valE;
d_srcA == e_dstM : e_valM;
1: reg_read.valA;
];
u64 d_valB = [
// BOOL_PLACEHOLDER : U64_PLACEHOLDER;
// BOOL_PLACEHOLDER : U64_PLACEHOLDER;
d_srcB == e_dstE : e_valE;
d_srcB == e_dstM : e_valM;
1: reg_read.valB;
];
:=======================: "Execute Stage (Execute)" :==========================:
u8 e_dstE = [
// U8_PLACEHOLDER == CMOVX && !BOOL_PLACEHOLDER : RNONE;
E.icode == CMOVX && !e_cnd : RNONE;
1 : E.dstE;
];
:========================: Pipeline Register Control :=========================:
// bool f_stall = D.icode in { U8_PLACEHOLDER, U8_PLACEHOLDER };
bool f_stall = D.icode in { JX, RET };
// bool d_bubble = D.icode in { U8_PLACEHOLDER, U8_PLACEHOLDER };
bool d_bubble = D.icode in { JX, RET };pipe_s3c.rs
在 pipe_s3c.rs 中,我们需要在 pipe_s3b.rs 的基础上进一步优化。pipe_s3b 的性能提升不是很显著,因为当遇到 JX 指令时,我们总是会停顿/产生气泡。实际上,我们在解码阶段就已知两种分支选项,只是必须等到执行阶段才能确定选择哪条分支,我们可以基于此实现分支预测。
pipe_s3c.rs 的占位符修改如下:
:==============================: Fetch Stage :================================:
u64 f_pc = [
// Call. Use instruction constant
// If the previous instruction is CALL, the constant value should be the next PC
// valC is from Fetch Stage, thus the last cycle
D.icode == CALL : D.valC;
// Branch misprediction. Use incremental PC
// U8_PLACEHOLDER == JX && !e_cnd : U64_PLACEHOLDER;
E.icode == JX && !e_cnd : E.valP;
// Completion of RET instruction. Use value from stack
// valM is from DEMW stage, thus the current cycle
// U8_PLACEHOLDER == RET : e_valM;
E.icode == RET : e_valM;
// Default: Use predicted PC
1 : F.pred_pc;
];
:==============================: Decode Stage :================================:
u64 d_valA = [
// d_srcA == U8_PLACEHOLDER : e_valE;
// d_srcA == U8_PLACEHOLDER : e_valM;
d_srcA == e_dstE : e_valE;
d_srcA == e_dstM : e_valM;
1: reg_read.valA;
];
u64 d_valB = [
// BOOL_PLACEHOLDER : U64_PLACEHOLDER;
// BOOL_PLACEHOLDER : U64_PLACEHOLDER;
d_srcB == e_dstE : e_valE;
d_srcB == e_dstM : e_valM;
1: reg_read.valB;
];
:=======================: "Execute Stage (Execute)" :==========================:
u8 e_dstE = [
// U8_PLACEHOLDER == CMOVX && !BOOL_PLACEHOLDER : RNONE;
E.icode == CMOVX && !e_cnd : RNONE;
1 : E.dstE;
];
:========================: Pipeline Register Control :=========================:
// If a branch misprediction is detected during the Execute stage, it means that
// the instruction currently in the Decode stage is invalid. Therefore, the next
// cycle’s Execute stage needs to insert a bubble.
// bool branch_mispred = BOOL_PLACEHOLDER;
bool branch_mispred = E.icode == JX && !e_cnd;
// If both a branch misprediction and a RET hazard occur at the same time, since
// the jump instruction is executed before the RET, the RET should not have been
// executed, so a stall is not needed.
// bool f_stall = BOOL_PLACEHOLDER && !BOOL_PLACEHOLDER;
bool f_stall = ret_harzard && !branch_mispred;
// If both a branch misprediction and a ret hazard occur at the same time,
// since the jump instruction is executed before the RET, the RET should not
// have been executed. Therefore, a bubble is not needed.
// bool d_bubble = BOOL_PLACEHOLDER && !BOOL_PLACEHOLDER;
bool d_bubble = ret_harzard && !branch_mispred;pipe_s3d.rs
在 pipe_s3d.rs 中,我们需要在 pipe_s3c.rs 的基础上进一步优化。从 pipe_s3c 到 pipe_s3d 的主要变化在于硬件设计。我们将寄存器读取和写入合并到一个名为 reg_file 的设备中,操作顺序为先写后读。此更改的目的是为了避免结构风险。
pipe_s3d.rs 的占位符修改如下:
:==============================: Fetch Stage :================================:
u64 f_pc = [
// Call. Use instruction constant
// If the previous instruction is CALL, the constant value should be the next PC
// valC is from Fetch Stage, thus the last cycle
D.icode == CALL : D.valC;
// Branch misprediction. Use incremental PC
// U8_PLACEHOLDER == JX && !e_cnd : U64_PLACEHOLDER;
E.icode == JX && !e_cnd : E.valP;
// Completion of RET instruction. Use value from stack
// valM is from DEMW stage, thus the current cycle
// U8_PLACEHOLDER == RET : e_valM;
E.icode == RET : e_valM;
// Default: Use predicted PC
1 : F.pred_pc;
];
:==============================: Decode Stage :================================:
u64 d_valA = [
// d_srcA == U8_PLACEHOLDER : e_valE;
// d_srcA == U8_PLACEHOLDER : e_valM;
d_srcA == e_dstE : e_valE;
d_srcA == e_dstM : e_valM;
1: reg_file.valA;
];
u64 d_valB = [
// BOOL_PLACEHOLDER : U64_PLACEHOLDER;
// BOOL_PLACEHOLDER : U64_PLACEHOLDER;
d_srcB == e_dstE : e_valE;
d_srcB == e_dstM : e_valM;
1: reg_file.valB;
];
:=======================: "Execute Stage (Execute)" :==========================:
u8 e_dstE = [
// U8_PLACEHOLDER == CMOVX && !BOOL_PLACEHOLDER : RNONE;
E.icode == CMOVX && !e_cnd : RNONE;
1 : E.dstE;
];
:========================: Pipeline Register Control :=========================:
// If a branch misprediction is detected during the Execute stage, it means that
// the instruction currently in the Decode stage is invalid. Therefore, the next
// cycle’s Execute stage needs to insert a bubble.
// bool branch_mispred = BOOL_PLACEHOLDER;
bool branch_mispred = E.icode == JX && !e_cnd;
// If both a branch misprediction and a RET hazard occur at the same time, since
// the jump instruction is executed before the RET, the RET should not have been
// executed, so a stall is not needed.
// bool f_stall = BOOL_PLACEHOLDER && !BOOL_PLACEHOLDER;
bool f_stall = ret_harzard && !branch_mispred;
// If both a branch misprediction and a ret hazard occur at the same time,
// since the jump instruction is executed before the RET, the RET should not
// have been executed. Therefore, a bubble is not needed.
// bool d_bubble = BOOL_PLACEHOLDER && !BOOL_PLACEHOLDER;
bool d_bubble = ret_harzard && !branch_mispred;pipe_s4a.rs
在 pipe_s4a.rs 中,我们需要在 pipe_s3d.rs 的基础上进一步优化。为了进一步减少计算依赖层级,我们已经将执行阶段与其他阶段分离。实际上,通过在 pipe_s3d 中强制对寄存器执行先写后读的顺序,我们可以避免可能在 pipe_s4 中发生的结构性冒险。
pipe_s4a.rs 的占位符修改如下:
:==============================: Fetch Stage :================================:
u64 f_pc = [
// Call. Use instruction constant
// If the previous instruction is CALL, the constant value should be the next PC
// valC is from Fetch Stage, thus the last cycle
D.icode == CALL : D.valC;
// Branch misprediction. Use incremental PC
// U8_PLACEHOLDER == JX && !e_cnd : U64_PLACEHOLDER;
E.icode == JX && !e_cnd : E.valP;
// Completion of RET instruction. Use value from stack
// valM is from DEMW stage, thus the current cycle
// U8_PLACEHOLDER == RET : U64_PLACEHOLDER;
M.icode == RET : m_valM;
// Default: Use predicted PC
1 : F.pred_pc;
];
:==============================: Decode Stage :================================:
u64 d_valA = [
// d_srcA == U8_PLACEHOLDER : e_valE;
// d_srcA == U8_PLACEHOLDER : U64_PLACEHOLDER;
d_srcA == e_dstE : e_valE;
d_srcA == m_dstM : m_valM;
1: reg_file.valA;
];
u64 d_valB = [
// BOOL_PLACEHOLDER : U64_PLACEHOLDER;
// BOOL_PLACEHOLDER : U64_PLACEHOLDER;
d_srcB == e_dstE : e_valE;
d_srcB == m_dstM : m_valM;
1: reg_file.valB;
];
:=============================: Execute Stage :================================:
u8 e_dstE = [
// U8_PLACEHOLDER == CMOVX && !BOOL_PLACEHOLDER : RNONE;
E.icode == CMOVX && !e_cnd : RNONE;
1 : E.dstE;
];
:========================: Pipeline Register Control :=========================:
// If a branch misprediction is detected during the Execute stage, it means that
// the instruction currently in the Decode stage is invalid. Therefore, the next
// cycle’s Execute stage needs to insert a bubble.
// bool branch_mispred = BOOL_PLACEHOLDER;
bool branch_mispred = E.icode == JX && !e_cnd;
// If a RET instruction is detected in either the Decode or Execute stage, then
// the instruction in the current Fetch stage is invalid. Therefore, a bubble
// needs to be inserted in the Fetch stage for the next cycle.
//
// In fact, when E.icode == RET, the instruction in the current Decode stage is
// also invalid, but because the D.icode in the previous cycle was RET, at this
// point D.icode == NOP, so there's no need to add a condition for e_bubble.
// bool ret_harzard = RET in { U8_PLACEHOLDER, U8_PLACEHOLDER };
bool ret_harzard = RET in { D.icode, E.icode };
// If both a branch misprediction and a RET hazard occur at the same time,
// since the jump instruction is executed before the RET, the RET should not be
// executed, so no stall is required.
// bool f_stall = BOOL_PLACEHOLDER && !BOOL_PLACEHOLDER || BOOL_PLACEHOLDER;
bool f_stall = ret_harzard && !branch_mispred || load_use_harzard;
// bool d_stall = BOOL_PLACEHOLDER;
bool d_stall = load_use_harzard;
// If both a branch misprediction and a RET hazard occur at the same time,
// since the jump instruction is executed before the RET, the RET should not
// have been executed, so a bubble is not needed.
//
// Actually, ret_harzard and d_stall cannot be true at the same time.
// bool d_bubble = BOOL_PLACEHOLDER && !BOOL_PLACEHOLDER && !d_stall;
bool d_bubble = ret_harzard && !branch_mispred && !d_stall;
// bool e_bubble = branch_mispred || BOOL_PLACEHOLDER;
bool e_bubble = branch_mispred || load_use_harzard;pipe_s4b.rs
在 pipe_s4b.rs 中,我们需要在 pipe_s4a.rs 的基础上进一步优化。我们注意到用于计算 f_pc 的 e_cnd 的依赖路径太长。因此,我们可以将 e_cnd 存储在存储阶段寄存器中,并用 M.cnd 替代它。
pipe_s4b.rs 的占位符修改如下:
:==============================: Fetch Stage :================================:
u64 f_pc = [
// Call. Use instruction constant
// If the previous instruction is CALL, the constant value should be the next PC
// valC is from Fetch Stage, thus the last cycle
D.icode == CALL : D.valC;
// Branch misprediction. Use incremental PC
// U8_PLACEHOLDER == JX && !M.cnd : U64_PLACEHOLDER;
M.icode == JX && !M.cnd : M.valP;
// Completion of RET instruction. Use value from stack
// valM is from DEMW stage, thus the current cycle
// U8_PLACEHOLDER == RET : U64_PLACEHOLDER;
M.icode == RET : m_valM;
// Default: Use predicted PC
1 : F.pred_pc;
];
:==============================: Decode Stage :================================:
u64 d_valA = [
// d_srcA == U8_PLACEHOLDER : e_valE;
// d_srcA == U8_PLACEHOLDER : U64_PLACEHOLDER;
d_srcA == e_dstE : e_valE;
d_srcA == m_dstM : m_valM;
1: reg_file.valA;
];
u64 d_valB = [
// BOOL_PLACEHOLDER : U64_PLACEHOLDER;
// BOOL_PLACEHOLDER : U64_PLACEHOLDER;
d_srcB == e_dstE : e_valE;
d_srcB == m_dstM : m_valM;
1: reg_file.valB;
];
:=============================: Execute Stage :================================:
u8 e_dstE = [
// U8_PLACEHOLDER == CMOVX && !BOOL_PLACEHOLDER : RNONE;
E.icode == CMOVX && !e_cnd : RNONE;
1 : E.dstE;
];
:========================: Pipeline Register Control :=========================:
// If a branch misprediction is detected during the Execute stage, it means that
// the instruction currently in the Decode stage is invalid. Therefore, the next
// cycle’s Execute stage needs to insert a bubble.
// bool branch_mispred = BOOL_PLACEHOLDER;
bool branch_mispred = E.icode == JX && !e_cnd;
// If a RET instruction is detected in either the Decode or Execute stage, then
// the instruction in the current Fetch stage is invalid. Therefore, a bubble
// needs to be inserted in the Fetch stage for the next cycle.
//
// In fact, when E.icode == RET, the instruction in the current Decode stage is
// also invalid, but because the D.icode in the previous cycle was RET, at this
// point D.icode == NOP, so there's no need to add a condition for e_bubble.
// bool ret_harzard = RET in { U8_PLACEHOLDER, U8_PLACEHOLDER };
bool ret_harzard = RET in { D.icode, E.icode };
// Unlike in `pipe_s4a`, here we do not need to consider the case of branch
// misprediction (since in the next cycle, Fetch will always get the `f_pc`
// from `M.valP`).
// bool f_stall = BOOL_PLACEHOLDER || BOOL_PLACEHOLDER;
bool f_stall = ret_harzard || load_use_harzard;
// bool d_stall = BOOL_PLACEHOLDER;
bool d_stall = load_use_harzard;
// Unlike in `pipe_s4a`, when a branch misprediction occurs, we directly insert
// a bubble, because the instruction in the Fetch stage at that point is invalid.
// Actually, ret_harzard and d_stall cannot be true at the same time.
// bool d_bubble = BOOL_PLACEHOLDER || BOOL_PLACEHOLDER && !d_stall;
bool d_bubble = branch_mispred || ret_harzard && !d_stall;
// bool e_bubble = branch_mispred || BOOL_PLACEHOLDER;
bool e_bubble = branch_mispred || load_use_harzard;pipe_s4c.rs
在 pipe_s4c.rs 中,我们需要在 pipe_s4b.rs 的基础上进一步优化。类似于 pipe_std.rs,我们在解码阶段将 D.valP 输入到 d_valA 中,以消除执行和存储阶段流水线寄存器中的 valP。
pipe_s4c.rs 的占位符修改如下:
:==============================: Fetch Stage :================================:
u64 f_pc = [
// Call. Use instruction constant
// If the previous instruction is CALL, the constant value should be the next PC
// valC is from Fetch Stage, thus the last cycle
D.icode == CALL : D.valC;
// Branch misprediction. Use incremental PC
// U8_PLACEHOLDER == JX && !M.cnd : U64_PLACEHOLDER;
M.icode == JX && !M.cnd : M.valA;
// Completion of RET instruction. Use value from stack
// valM is from DEMW stage, thus the current cycle
// U8_PLACEHOLDER == RET : U64_PLACEHOLDER;
M.icode == RET : m_valM;
// Default: Use predicted PC
1 : F.pred_pc;
];
:==============================: Decode Stage :================================:
u64 d_valA = [
D.icode in { CALL, JX } : D.valP;
// d_srcA == U8_PLACEHOLDER : e_valE;
// d_srcA == U8_PLACEHOLDER : U64_PLACEHOLDER;
d_srcA == e_dstE : e_valE;
d_srcA == m_dstM : m_valM;
1: reg_file.valA;
];
u64 d_valB = [
// BOOL_PLACEHOLDER : U64_PLACEHOLDER;
// BOOL_PLACEHOLDER : U64_PLACEHOLDER;
d_srcB == e_dstE : e_valE;
d_srcB == m_dstM : m_valM;
1: reg_file.valB;
];
:=============================: Execute Stage :================================:
u8 e_dstE = [
// U8_PLACEHOLDER == CMOVX && !BOOL_PLACEHOLDER : RNONE;
E.icode == CMOVX && !e_cnd : RNONE;
1 : E.dstE;
];
:==============================: Memory Stage :================================:
// We've feed D.valP into d_valA. Thus M.valP is not needed.
// u64 mem_data = U64_PLACEHOLDER;
u64 mem_data = M.valA;
:========================: Pipeline Register Control :=========================:
// If a branch misprediction is detected during the Execute stage, it means that
// the instruction currently in the Decode stage is invalid. Therefore, the next
// cycle’s Execute stage needs to insert a bubble.
// bool branch_mispred = BOOL_PLACEHOLDER;
bool branch_mispred = E.icode == JX && !e_cnd;
// If a RET instruction is detected in either the Decode or Execute stage, then
// the instruction in the current Fetch stage is invalid. Therefore, a bubble
// needs to be inserted in the Fetch stage for the next cycle.
//
// In fact, when E.icode == RET, the instruction in the current Decode stage is
// also invalid, but because the D.icode in the previous cycle was RET, at this
// point D.icode == NOP, so there's no need to add a condition for e_bubble.
// bool ret_harzard = RET in { U8_PLACEHOLDER, U8_PLACEHOLDER };
bool ret_harzard = RET in { D.icode, E.icode };
// Unlike in `pipe_s4a`, here we do not need to consider the case of branch
// misprediction (since in the next cycle, Fetch will always get the `f_pc`
// from `M.valP`).
// bool f_stall = BOOL_PLACEHOLDER || BOOL_PLACEHOLDER;
bool f_stall = ret_harzard || load_use_harzard;
// bool d_stall = BOOL_PLACEHOLDER;
bool d_stall = load_use_harzard;
// Unlike in `pipe_s4a`, when a branch misprediction occurs, we directly insert
// a bubble, because the instruction in the Fetch stage at that point is invalid.
// Actually, ret_harzard and d_stall cannot be true at the same time.
// bool d_bubble = BOOL_PLACEHOLDER || BOOL_PLACEHOLDER && !d_stall;
bool d_bubble = branch_mispred || ret_harzard && !d_stall;
// bool e_bubble = branch_mispred || BOOL_PLACEHOLDER;
bool e_bubble = branch_mispred || load_use_harzard;Part C
Part C 中,我们将在 archlab-project/misc 和 archlab-project/sim/src/architectures/extra 目录下开展工作。我们的任务是修改 archlab-project/misc/ncopy.ys 和 archlab-project/sim/src/architectures/extra/ncopy.rs,让 ncopy 运行得尽可能快。最终性能将根据 cpe 和 ac 来评估。
- cpe (cycles per element):如果模拟代码需要 C 个周期来复制一个包含 N 个元素的块,那么 CPE 就是 C/N。
- ac (architecture cost):ncopy 架构的关键路径长度。形式上,CPU 架构的关键路径是时钟元件之间组合逻辑的最长路径。关键路径的长度可以用来衡量 CPU 的时钟频率,从而用于估算架构性能。在 Part C 中,关键路径的长度简化为:1 加上在架构路径中排列的硬件设备(单元)的最大数量。
ncopy 的 C 语言描述在 misc/ncopy.c 中。ncopy 函数将一个长度为 len 的整数数组 src 复制到一个不重叠的 dst 中,并返回 src 中正整数的数量。
#include <stdio.h>
typedef unsigned long long word_t;
word_t src[8], dst[8];
/* $begin ncopy */
/*
* ncopy - copy src to dst, returning number of positive ints
* contained in src array.
*/
word_t ncopy(word_t *src, word_t *dst, word_t len) {
word_t count = 0;
word_t val;
while (len > 0) {
val = *src++;
*dst++ = val;
if (val > 0)
count++;
len--;
}
return count;
}
/* $end ncopy */
int main() {
word_t i, count;
for (i = 0; i < 8; i++)
src[i] = i + 1;
count = ncopy(src, dst, 8);
printf("count=%d\n", count);
exit(0);
}应用 PIPE 架构
由于 ncopy.rs 初始是 SEQ 架构,我们用 archlab-project/sim/src/architectures/builtin/pipe_std.rs 的内容完整替换 ncopy.rs 文件的内容。初步优化处理器架构,减少 ac。
添加 IOPQ 指令
查看 ncopy.ys 中的初始汇编代码。
################################################################################
# ncopy.ys - Copy a src block of len words to dst.
# Return the number of positive words (>0) contained in src.
################################################################################
# Do not modify this portion
# Function prologue.
# %rdi = src, %rsi = dst, %rdx = len
ncopy:
################################################################################
# You can modify this portion
# Loop header
xorq %rax,%rax # count = 0;
andq %rdx,%rdx # len <= 0?
jle Done # if so, goto Done:
Loop:
mrmovq (%rdi), %r10 # read val from src...
rmmovq %r10, (%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle Npos # if so, goto Npos:
irmovq $1, %r10
addq %r10, %rax # count++
Npos:
irmovq $1, %r10
subq %r10, %rdx # len--
irmovq $8, %r10
addq %r10, %rdi # src++
addq %r10, %rsi # dst++
andq %rdx,%rdx # len > 0?
jg Loop # if so, goto Loop:
Done:
ret
# In grader, we will add a "trap: jmp trap" here, which traps your program in an
# infinite loop. Thus your function should always return instead of falling
# through till the end of the source code :)发现每次进行 count++ 时,都需要先 irmovq 将立即数 1 加载到寄存器中,然后再进行加法操作。我们可以使用 IOPQ 指令来直接将立即数与寄存器相加,从而减少指令数量和执行时间。为此,我们需要在 ncopy.rs 中添加 IOPQ 指令。具体步骤可参考 Part B 部分针对 seq_full.rs 的修改。
循环展开
至此,我们已经将架构从 SEQ 升级到了 PIPE,并通过 IOPQ 指令减少了指令数量。进一步观察发现,每一次循环最后都需要经历一次条件跳转,这意味着每次循环都要经历控制冒险,但却只处理了一个元素。我们可以通过循环展开,在一次循环中处理多个元素来进一步提升 cpe。
循环展开参考代码如下:
Loop:
mrmovq (%rdi), %rcx
mrmovq 8(%rdi), %rbx
mrmovq 16(%rdi), %rbp
mrmovq 24(%rdi), %r8
mrmovq 32(%rdi), %r9
mrmovq 40(%rdi), %r10
mrmovq 48(%rdi), %r11
mrmovq 56(%rdi), %r12
mrmovq 64(%rdi), %r13
mrmovq 72(%rdi), %r14
L1:
rmmovq %rcx, (%rsi)
andq %rcx, %rcx
jle L2
iaddq $1, %rax
L2:
rmmovq %rbx, 8(%rsi)
andq %rbx, %rbx
jle L3
iaddq $1, %rax
L3:
rmmovq %rbp, 16(%rsi)
andq %rbp, %rbp
jle L4
iaddq $1, %rax
L4:
rmmovq %r8, 24(%rsi)
andq %r8, %r8
jle L5
iaddq $1, %rax
L5:
rmmovq %r9, 32(%rsi)
andq %r9, %r9
jle L6
iaddq $1, %rax
L6:
rmmovq %r10, 40(%rsi)
andq %r10, %r10
jle L7
iaddq $1, %rax
L7:
rmmovq %r11, 48(%rsi)
andq %r11, %r11
jle L8
iaddq $1, %rax
L8:
rmmovq %r12, 56(%rsi)
andq %r12, %r12
jle L9
iaddq $1, %rax
L9:
rmmovq %r13, 64(%rsi)
andq %r13, %r13
jle L10
iaddq $1, %rax
L10:
rmmovq %r14, 72(%rsi)
andq %r14, %r14
jle N
iaddq $1, %rax
N:
iaddq $80, %rdi # src++
iaddq $80, %rsi # dst++
isubq $10, %rdx # len--
jge Loop # if so, goto Loop余数二分处理
循环展开带来的问题是当 len 不是展开倍数时,剩余的元素无法通过展开后的循环处理。为了解决这个问题,我们需要针对不同的余数情况编写不同的处理代码,形成类似跳转表的结构。为了避免代码重复和过多的跳转,我们可以针对每个剩余的元素编写处理代码,Rk 对应对第 k 个剩余元素的处理,然后将这些代码块按照从大到小串联起来。对于不同的余数情况,我们只需要跳转到对应的 Rk 代码块即可,程序会顺序执行后续的对第 k-1、k-2、...、1 个剩余元素的处理代码。
余数处理参考代码如下:
R9:
mrmovq 64(%rdi), %rcx
andq %rcx, %rcx
rmmovq %rcx, 64(%rsi)
jle R8
iaddq $1, %rax
R8:
mrmovq 56(%rdi), %rcx
andq %rcx, %rcx
rmmovq %rcx, 56(%rsi)
jle R7
iaddq $1, %rax
R7:
mrmovq 48(%rdi), %rcx
andq %rcx, %rcx
rmmovq %rcx, 48(%rsi)
jle R6
iaddq $1, %rax
R6:
mrmovq 40(%rdi), %rcx
andq %rcx, %rcx
rmmovq %rcx, 40(%rsi)
jle R5
iaddq $1, %rax
R5:
mrmovq 32(%rdi), %rcx
andq %rcx, %rcx
rmmovq %rcx, 32(%rsi)
jle R4
iaddq $1, %rax
R4:
mrmovq 24(%rdi), %rcx
andq %rcx, %rcx
rmmovq %rcx, 24(%rsi)
jle R3
iaddq $1, %rax
R3:
mrmovq 16(%rdi), %rcx
andq %rcx, %rcx
rmmovq %rcx, 16(%rsi)
jle R2
iaddq $1, %rax
R2:
mrmovq 8(%rdi), %rcx
andq %rcx, %rcx
rmmovq %rcx, 8(%rsi)
jle R1
iaddq $1, %rax
R1:
mrmovq (%rdi), %rcx
andq %rcx, %rcx
rmmovq %rcx, (%rsi)
jle Done
iaddq $1, %rax注意这里将 andq 指令插入到 mrmovq 和 rmmovq 之间,从而避免了流水线暂停。
至于跳转部分,我们可以对余数反复减一并判断是否为零来跳转到对应的代码块。也可以选择使用二分思想来减少跳转次数。
完整 ncopy.ys 参考代码如下:
################################################################################
# ncopy.ys - Copy a src block of len words to dst.
# Return the number of positive words (>0) contained in src.
################################################################################
# Do not modify this portion
# Function prologue.
# %rdi = src, %rsi = dst, %rdx = len
ncopy:
################################################################################
# You can modify this portion
# Loop header
xorq %rax,%rax # count = 0;
isubq $10, %rdx
jl R
Loop:
mrmovq (%rdi), %rcx
mrmovq 8(%rdi), %rbx
mrmovq 16(%rdi), %rbp
mrmovq 24(%rdi), %r8
mrmovq 32(%rdi), %r9
mrmovq 40(%rdi), %r10
mrmovq 48(%rdi), %r11
mrmovq 56(%rdi), %r12
mrmovq 64(%rdi), %r13
mrmovq 72(%rdi), %r14
L1:
rmmovq %rcx, (%rsi)
andq %rcx, %rcx
jle L2
iaddq $1, %rax
L2:
rmmovq %rbx, 8(%rsi)
andq %rbx, %rbx
jle L3
iaddq $1, %rax
L3:
rmmovq %rbp, 16(%rsi)
andq %rbp, %rbp
jle L4
iaddq $1, %rax
L4:
rmmovq %r8, 24(%rsi)
andq %r8, %r8
jle L5
iaddq $1, %rax
L5:
rmmovq %r9, 32(%rsi)
andq %r9, %r9
jle L6
iaddq $1, %rax
L6:
rmmovq %r10, 40(%rsi)
andq %r10, %r10
jle L7
iaddq $1, %rax
L7:
rmmovq %r11, 48(%rsi)
andq %r11, %r11
jle L8
iaddq $1, %rax
L8:
rmmovq %r12, 56(%rsi)
andq %r12, %r12
jle L9
iaddq $1, %rax
L9:
rmmovq %r13, 64(%rsi)
andq %r13, %r13
jle L10
iaddq $1, %rax
L10:
rmmovq %r14, 72(%rsi)
andq %r14, %r14
jle N
iaddq $1, %rax
N:
iaddq $80, %rdi # src++
iaddq $80, %rsi # dst++
isubq $10, %rdx # len--
jge Loop # if so, goto Loop
R:
iaddq $10, %rdx
jle Done
isubq $5, %rdx
je R5
jg R6_9
R1_4:
iaddq $2, %rdx
jl R1_2
R3_4:
je R3
jmp R4
R1_2:
iaddq $1, %rdx
je R2
jmp R1
R6_9:
isubq $2, %rdx
jg R8_9
R6_7:
je R7
jmp R6
R8_9:
isubq $1, %rdx
je R8
R9:
mrmovq 64(%rdi), %rcx
andq %rcx, %rcx
rmmovq %rcx, 64(%rsi)
jle R8
iaddq $1, %rax
R8:
mrmovq 56(%rdi), %rcx
andq %rcx, %rcx
rmmovq %rcx, 56(%rsi)
jle R7
iaddq $1, %rax
R7:
mrmovq 48(%rdi), %rcx
andq %rcx, %rcx
rmmovq %rcx, 48(%rsi)
jle R6
iaddq $1, %rax
R6:
mrmovq 40(%rdi), %rcx
andq %rcx, %rcx
rmmovq %rcx, 40(%rsi)
jle R5
iaddq $1, %rax
R5:
mrmovq 32(%rdi), %rcx
andq %rcx, %rcx
rmmovq %rcx, 32(%rsi)
jle R4
iaddq $1, %rax
R4:
mrmovq 24(%rdi), %rcx
andq %rcx, %rcx
rmmovq %rcx, 24(%rsi)
jle R3
iaddq $1, %rax
R3:
mrmovq 16(%rdi), %rcx
andq %rcx, %rcx
rmmovq %rcx, 16(%rsi)
jle R2
iaddq $1, %rax
R2:
mrmovq 8(%rdi), %rcx
andq %rcx, %rcx
rmmovq %rcx, 8(%rsi)
jle R1
iaddq $1, %rax
R1:
mrmovq (%rdi), %rcx
andq %rcx, %rcx
rmmovq %rcx, (%rsi)
jle Done
iaddq $1, %rax
Done:
ret
# In grader, we will add a "trap: jmp trap" here, which traps your program in an
# infinite loop. Thus your function should always return instead of falling
# through till the end of the source code :)减少关键路径长度
目前我们的 ncopy.rs 采用的是 PIPE 架构,关键路径长度为 4,正是执行阶段 e_cnd 的依赖路径。
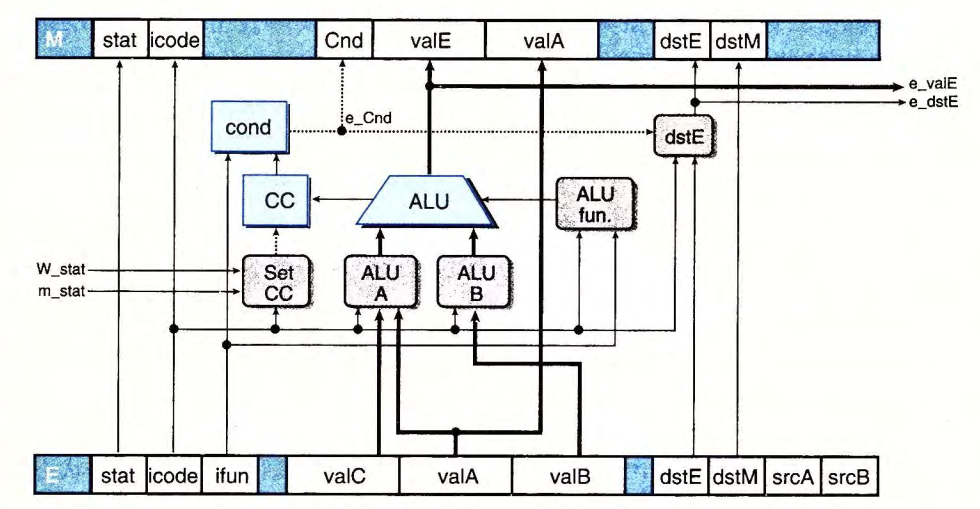
回忆 dstE 需要 e_cnd 更新的情况,为条件传送 CMOVX 指令。而 CMOVX 指令并不更新条件码。由此可知,更新条件码和需要计算 e_cnd 更新 dstE 的情况不会在执行阶段同时发生。因此,我们可以在执行阶段寄存器中新增 pre_cc 记录上一条指令的条件码,用于通过 cond 单元计算 e_cnd,从而降低关键路径长度为 3。
ncopy.rs 参考修改如下:
crate::define_stages! {
// ...
ExecuteStage e {
stat: Stat = Bub, icode: u8 = NOP, ifun: u8 = 0,
valC: u64 = 0,
valA: u64 = 0, valB: u64 = 0,
dstE: u8 = RNONE, dstM: u8 = RNONE,
srcA: u8 = RNONE, srcB: u8 = RNONE,
pre_cc: ConditionCode = CC_INIT
}
// ...
}
sim_macro::hcl! {
// ...
:==============================: Fetch Stage :================================:
// ...
:=======================: Decode and Write Back Stage :=======================:
// ...
@set_stage(e, {
icode: d_icode,
ifun: d_ifun,
stat: d_stat,
valC: d_valC,
srcA: d_srcA,
srcB: d_srcB,
valA: d_valA,
valB: d_valB,
dstE: d_dstE,
dstM: d_dstM,
pre_cc: cc,
});
:==============================: Execute Stage :===============================:
// ...
ConditionCode cc = reg_cc.cc;
u8 e_ifun = E.ifun;
ConditionCode pre_cc = E.pre_cc;
@set_input(cond, {
cc: pre_cc,
condfun: e_ifun,
});
// ...
:===============================: Memory Stage :===============================:
// ...
:=============================: Write Back Stage :=============================:
// ...
:========================: Pipeline Register Control :=========================:
// ...
}